
PythonでSeleniumを使ってスクレイピングしてみる
pythonでスクレイピングをしてみたときのメモ
スクレイピングとは?
スクレイピングはWebサイトから欲しい情報を収集する技術のこと。
今回はpythonを使いそれを自動化してみる。
Seleniumとは?
Seleniumはブラウザの自動テストを行うためのライブラリらしい、それを利用してプログラム(Python)からブラウザを操作して情報を取って来よう!ということしたのでメモ。
Seleniumを使うとjavascriptが実行されたあとのhtmlが取得できる。
また、プログラムからブラウザを操作できる。たとえば、
・要素を指定してクリックしたり、キーを押したりできる
・要素を指定してテキストを入力できる
Seleniumを使ってのスクレイピングのながれ
下のような感じでプログラムを描いていく。
要素を取得する方法はいくつか用意されている。
- CSSセレクタで要素を指定
- XPathで要素を指定
- タグ名で要素を指定
などがある。
目的のデータに応じてこんな感じのことをする、
画像の場合は、imgタグのsrc属性から画像のurlを取得
取得したurlを使ってrequestsなどを使い画像をダウンロード
リンクの場合はaタグのhref属性からurlを取得
取得したurlを使いページ遷移したりする
属性を取得するには取得した要素のget_attributeメソッドを使う
テキストの場合はtextプロパティを使う
コードは下に記載
環境整備
ブラウザのインストール
たぶんブラウザ(ChromeとかFirefoxとか)もインストールしないと動かない。


webdriverを入手
使いたいブラウザに合わせて「webdriver + chrome」、「webdriver + firefox」などで検索してドライバーを入手。
使いたいブラウザのバージョンにあったものにする必要がある。
GoogleChrome
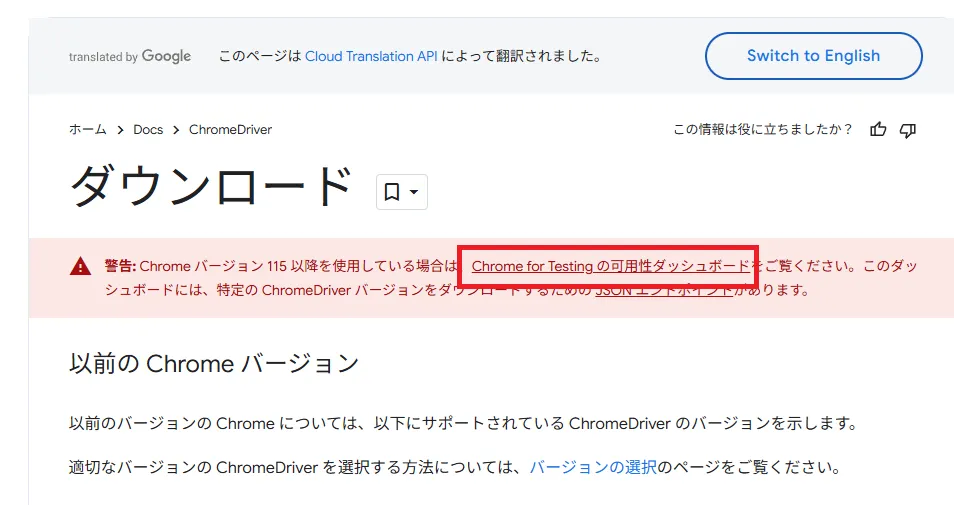
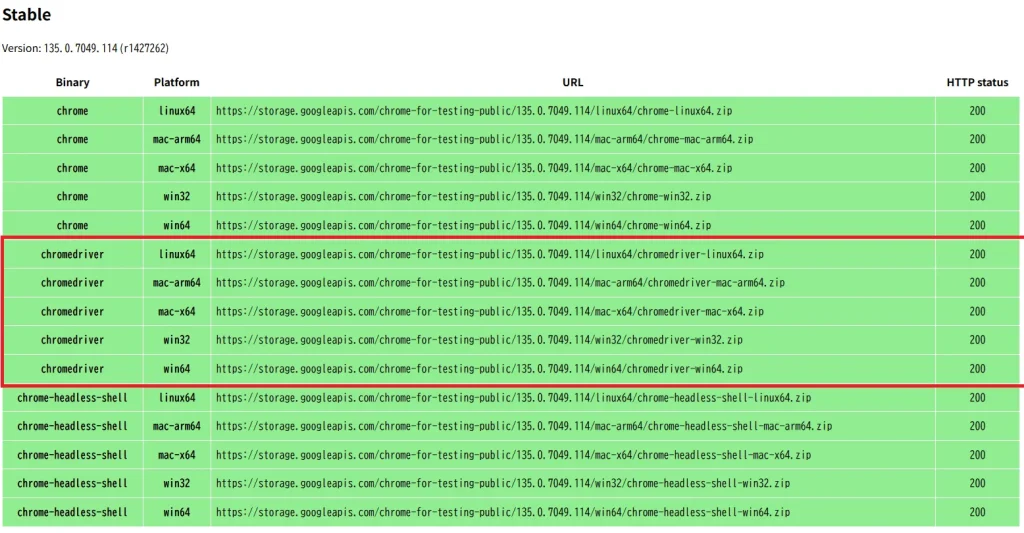
Chromeのドライバーはこちらから、
「chromedriver.exe」がドライバー本体。このファイルを適当な場所に配置。
FireFox
FireFoxのドライバーはこちらから、
「geckodriver.exe」がドライバー本体。このファイルを適当な場所に配置。
Microsoft Edge
Microsoft Edgeのドライバーはこちらから、

「msedgedriver.exe」がドライバー本体。このファイルを適当な場所に配置。
seleniumをインストールする
コマンドプロンプトで以下のコマンドを実行
pip install selenium以下のコマンドでインストールされたか確認
pip list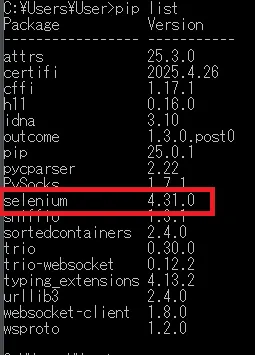
Seleniumでブラウザを起動
今回はchromeで試した。
使用したseleniumのバージョンは4.31.0
指定したURLのページを開く
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
url = '開きたいURL'
driverpath = 'webdriverのパス'
service = Service(executable_path=driverpath)
with webdriver.Chrome(service=service) as driver:
driver.get(url)withを使うと、withを抜けるとブラウザを閉じてくれる
ブラウザを非表示で実行する
Headlessモードというらしい。
optionを指定してwebdiverに渡す。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
url = '開きたいURL'
driverpath = 'webdriverのパス'
chrome_op = Options()
chrome_op.add_argument('--headless')
service = Service(executable_path=driverpath)
with webdriver.Chrome(service=service, options=chrome_op) as driver:
driver.get(url)要素の取得
見つかった最初の要素1つを返すメソッド(find_element)と、
見つかった要素すべてを返すメソッド(find_elements)
がある。
find_element系の戻り値のオブジェクトも同じメソッドを持っていて、見つかった要素の子要素のみを対象にまた検索するということができる。戻り値はおそらくWebElementクラス
find_elementは指定した要素が見つからないとエラーになる。
回避したいときはfind_elementsを使ってWebElementのリストを受け取りその長さを判定したりする。
それぞれ第1引数に検索対象を指定して、第2引数に検索条件を指定する感じ。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By #これを追加
url = '開きたいURL'
driverpath = 'webdriverのパス'
service = Service(executable_path=driverpath)
with webdriver.Chrome(service=service, options=chrome_op) as driver:
driver.get(url)
element1 = driver.find_element(By.ID, 'xxxxxxx')
element1 = driver.find_element(By.XPATH, 'xxxxxxx')
element1 = driver.find_element(By.LINK_TEXT, 'xxxxxxx')
element1 = driver.find_element(By.PARTIAL_LINK_TEXT, 'xxxxxxx')
element1 = driver.find_element(By.NAME, 'xxxxxxx')
element1 = driver.find_element(By.TAG_NAME, 'xxxxxxx')
element1 = driver.find_element(By.CLASS_NAME, 'xxxxxxx')
element1 = driver.find_element(By.CSS_SELECTOR, 'xxxxxxx')
elementList = driver.find_elements(By.ID, 'xxxxxxx')
elementList = driver.find_elements(By.XPATH, 'xxxxxxx')
elementList = driver.find_elements(By.LINK_TEXT, 'xxxxxxx')
elementList = driver.find_elements(By.PARTIAL_LINK_TEXT, 'xxxxxxx')
elementList = driver.find_elements(By.NAME, 'xxxxxxx')
elementList = driver.find_elements(By.TAG_NAME, 'xxxxxxx')
elementList = driver.find_elements(By.CLASS_NAME, 'xxxxxxx')
elementList = driver.find_elements(By.CSS_SELECTOR, 'xxxxxxx')Byで指定できるのは以下、
| 値 | 説明 |
|---|---|
| By.ID | 指定したidを持つ要素を取得 find_element(By.ID, ‘xxxxxxx’) <div id=”xxxxxxx”></div> |
| By.XPATH | 指定したxpath構文を使って要素を取得 |
| By.LINK_TEXT | 指定したリンクテキストを持つ要素を取得 find_element(By.LINK_TEXT, ‘リンク’) <a href=”aaa”>リンク</a> |
| By.PARTIAL_LINK_TEXT | 指定した文字列を含むリンクテキストを持つ要素を取得 find_element(By.PARTIAL_LINK_TEXT, ‘ンク’) <a href=”aaa”>リンク</a> |
| By.NAME | 指定したname属性値を持つ要素を取得 find_element(By.NAME, ‘xxxxxxx’) <div name=”xxxxxxx”></div> |
| By.TAG_NAME | 指定したタグ名を持つ要素を取得 find_element(By.TAG_NAME, ‘div’) <div></div> |
| By.CLASS_NAME | 指定したclass属性値を持つ要素を取得 find_element(By.CLASS_NAME, ‘xxxxxxx’) <div class=”xxxxxxx”></div> |
| By.CSS_SELECTOR | 指定したcssセレクタを使って要素を取得 |
属性の取得
取得した要素のget_attributeメソッドを使う
引数に属性名を指定する
<div id=”yasnote” class=”c1″/>
からclassの値を取りたい場合、
# id=yasnoteの要素を検索
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# 要素からclassの値を取り出す
class_value = element1.get_attribute('class')
print(class_value)テキストの取得
textプロパティを使う
<div id=”yasnote”>AAAAA</div>
からテキストの値を取りたい場合、
# id=yasnoteの要素を検索
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# テキストを取得、というか表示
print(element1.text)非表示なテキストの取得
hiddenだったり、<title>タグなんかはtextプロパティを使うと空文字が取れてくる。
get_attribute(‘textContent’)を使うとテキストが取れる
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
txt = element1.get_attribute("textContent")
print(txt)ブラウザの操作
以下を組み合わせるとユーザー名とかパスワードを入力してログインボタンをクリックなんてことができる。
クリック
選択した要素のclickメソッドを使う
<div id=”yasnote”/>を選択してクリックする場合、
# クリックしたい要素を取得
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# クリック
element1.click()テキスト入力
選択した要素のsend_keysメソッドを使う
引数に入力したテキストを指定する
# 入力したい要素を取得
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# 入力
element1.send_keys('aaaabbcc')キー入力
こちらも選択した要素のsend_keysメソッドを使う
引数にキーを指定する(Keys.XXX)
# Keysをインポート
from selenium.webdriver.common.keys import Keys
# キー入力したい要素を取得
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# キー入力(↑キー)
element1.send_keys(Keys.UP)Enterキーとか、方向キーとかいろいろ入力できる
Keysの一覧は以下を参照した
javascriptの実行
Pythonプログラムから起動したブラウザでjavascriptを実行できる
webdriverのexecute_scriptメソッドまたは、execute_async_scriptメソッドを使う
execute_async_scriptはjavascriptの中でリクエストを投げたり非同期処理を行う場合に使う
それぞれのメソッドの引数には、
第1引数にスクリプトを書いた文字列、
第2引数以降にスクリプトに渡す変数を指定する(可変長)
引数に指定した変数はargumentsという名前の配列でスクリプト内に渡される
スクリプト内の変数に代入したりして使う
execute_scriptメソッドの場合はスクリプト内でreturnで結果を返す
# 実行したいスクリプト
script = """
var arg1 = arguments[0];
var arg2 = arguments[1];
return arg1 + 100;
"""
# 実行して結果を受け取る
ret = driver.execute_script(script, 10, 20)
# 結果を表示
print(ret)execute_async_scriptメソッドの場合はスクリプト内でcallback(返したい値)で結果を返す
callback用のオブジェクトはargumentsの最後尾に入っている(4行目)
# 実行したいスクリプト
script = """
var arg1 = arguments[0];
var callback = arguments[arguments.length - 1];
var xhr = new XMLHttpRequest();
xhr.onload = function(){ callback(xhr.responseText) };
xhr.open('GET', arg1);
xhr.send();
"""
# 実行して結果を受け取る
ret = driver.execute_async_script(script, 'jsonが返ってくるurl')
# 結果を表示
print(ret)requests.getを使って画像をダウンロード
requests.getを使うと指定したURLのコンテンツを取得することができるのでそれを使って画像のURLを渡すと画像データをダウンロードすることができる。
画像データ(バイナリデータ)はrequests.getの戻り値(Response)のcontentから取得することができる。
そのバイナリデータをPythonの標準機能でファイルに書き出す感じで保存完了。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import requests
url = '開きたいURL'
driverpath = 'webdriverのパス'
service = Service(executable_path=driverpath)
with webdriver.Chrome(service=service, options=chrome_op) as driver:
driver.get(url)
# 画像のURLがある要素を取得
element1 = driver.find_element(By.CSS_SELECTOR, '[id="yasnote"]')
# 画像のURLを取得
img_url= element1.get_attribute('href')
#画像をダウンロード
response = requests.get(img_url)
#画像を保存
img_save_name = '保存する画像の名前'
with open(img_save_name, 'wb') as f:
f.write(response.content)「img_save_name」に代入する値を「001.jpg」とかにするとその名前で保存される。
ファイル名だけだとカレントディレクトリになるので変えたい場合はフルパス(「d:\001.jpg」とか)で書く。
画像URLから拡張子を取得
画像ファイルの拡張子をURLから取得したいときは「os.path.splitext」が便利。
import os
img_url = '/aaaa/bbbb/ccc.jpg'
result = os.path.splitext(img_url)
print(result)
# ('/aaaa/bbbb/ccc', '.jpg')
# ↑ result[0]に拡張子までの文字列
# result[1]に拡張子の文字列が入っている